
先上代码:
1 | import requests |
结果截图:
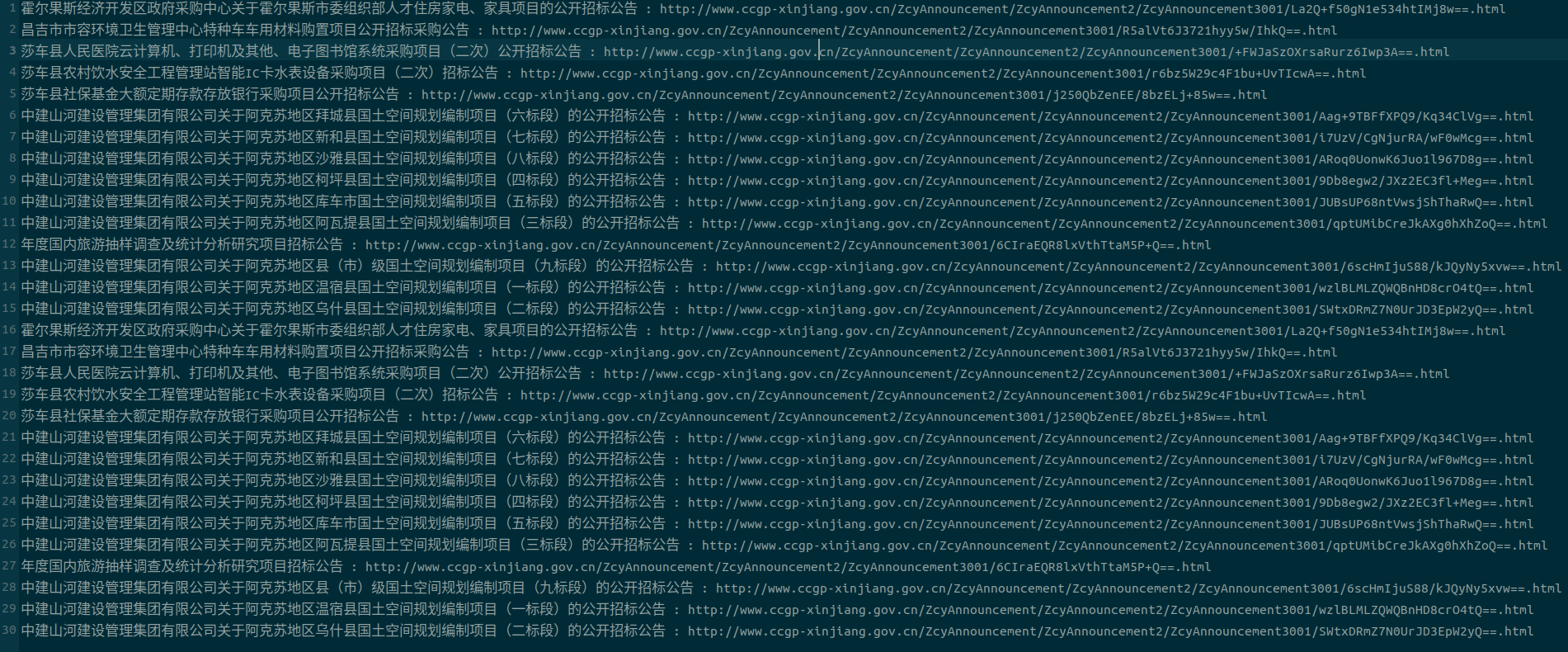
分析:
要求是获取到招标信息的前三页内容。观察目标网站
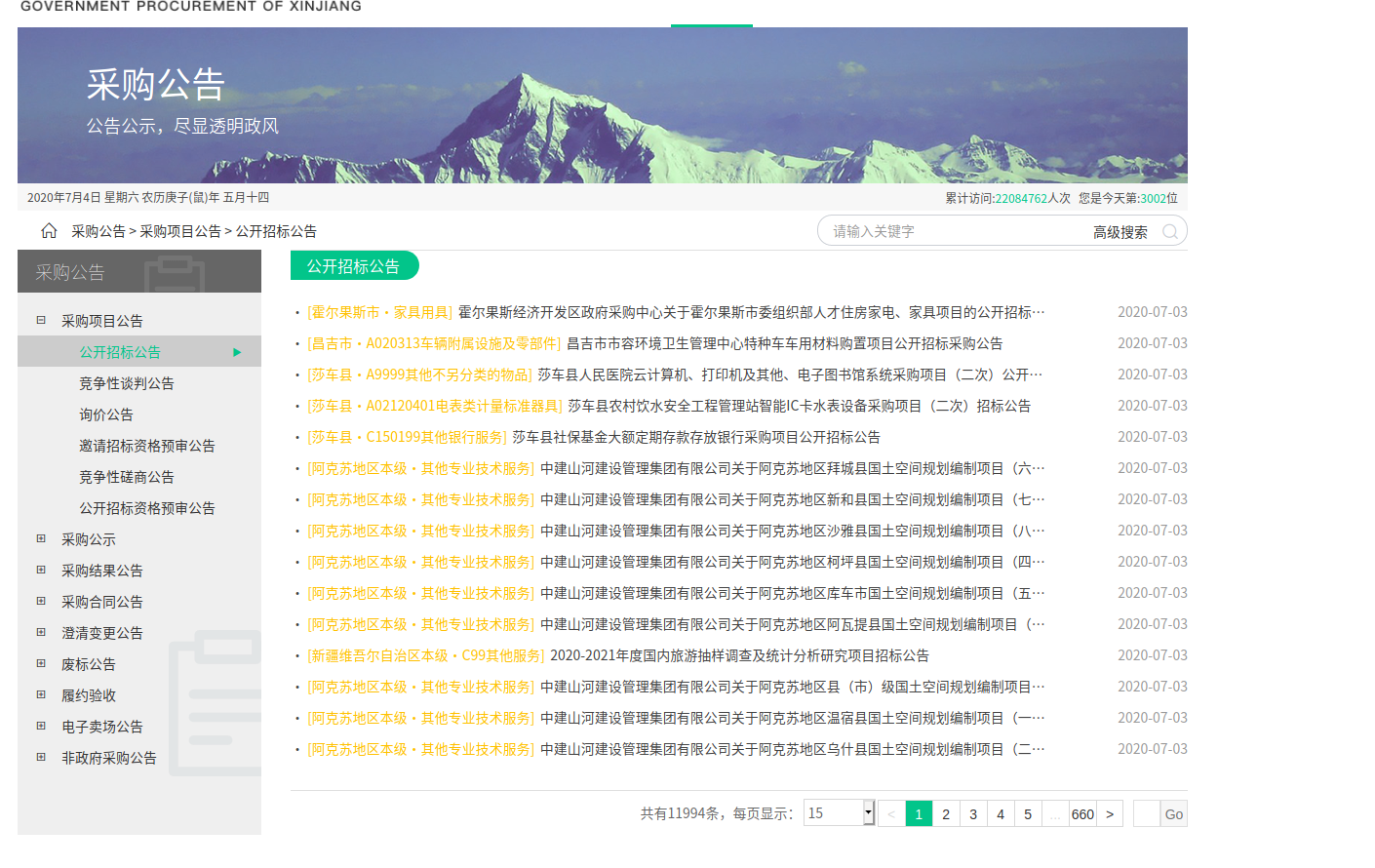
黄体字后面就是我们所需要的信息,点击下面的页面,如第二页,发现页面的URL并没有发生变化。所以打开调试模式
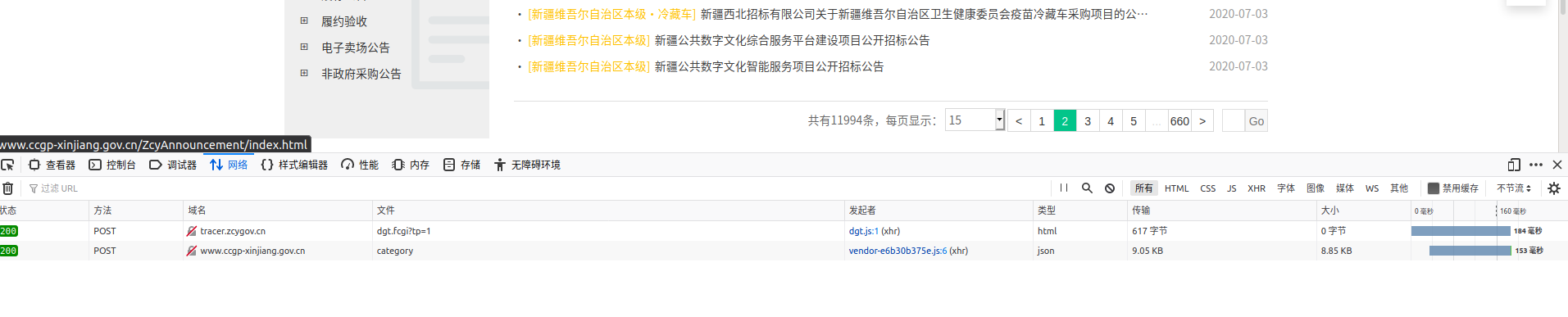
点击第二页,发现有两次请求,那么这两个请求里会有一个返回第二页的数据。第二页的数据如下:

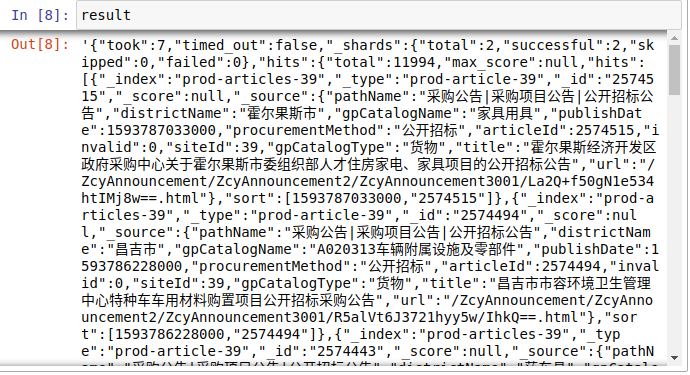
打开返回的json文件发现了第二页的内容

观察这json,我们所需要的信息都在’title’和’url’里。
问题来了,怎么获得这个json文件
在调试模式里选择编辑重发,发现:
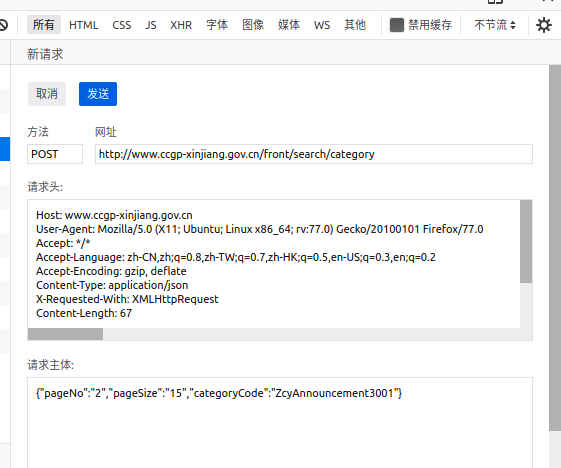
那么获取json文件就有了个思路。通过request的post请求,添加headers参数与请求主体。代码部分见文章最开始部分。
获取到了json文件,当然可以通过处理json文件的方式获取需要的信息。本文采用的爬虫中常常需要用到的正则(因为应用的更加的广泛)。
观察json文件的格式,title后面就是对应着相关网站的名称,而后面的url则是部分的URL。如图
那么获取标题和URL,可以使用re.finditer来获得所有的标题和URL,正则部分,自行查阅。
下面就是将获取到的标题列表和URL列表(注意:这里的URL并不是完整的URL,需要进行拼接,操作如上文)格式化的写入到文本中,就大功告成辣~
本文作者:
klig0day
版权声明:转载请注明出处!
文章说明: 文章如有不足或者纰漏之处,欢迎留言斧正!
版权声明:转载请注明出处!
文章说明: 文章如有不足或者纰漏之处,欢迎留言斧正!

